Memory Dropbox · event-sourced memory substrate experiment¶
memory-dropbox is the event-sourced memory substrate experiment in the stack. It’s where derived memories, observation memories, ingestion memories, and agent-facing memory experiments get to be first-class in a larger multi-service deployment — Postgres as the system of record, Redis as the queue, Qdrant as the vector store, a worker process for slow derived work.
It is not the canonical local memory core for this stack. That role belongs to earth-database, which is the smaller embedded sibling where the trust layer, provenance, and observability discipline get built first on a short hot path. This repo is the sibling where those same disciplines get tested at larger scope.
Repository: github.com/obversary/memory-dropbox
Shorter tagline: event-first memory infrastructure for inspectable AI systems.
Why an event-first substrate at larger scope¶
Most “memory” in AI stacks I’ve read is retrieval. Store chunks. Embed. Search. Return. That works as a feature; it doesn’t work as memory. There’s no record of when something was captured, no record of what events that capture produced, no derived layer where the system can have its own running interpretation of the input. It’s a filing cabinet with a search box.
The local canonical core (earth-database) enforces event-first memory at a small scale where the discipline is obvious. This repo is where the same pattern gets tested at larger scope — the point is to find out what breaks, what scales, and which parts of the event-sourced discipline survive the transition from one SQLite file to a multi-service deployment.
I want the substrate to behave more like how my own memory actually works:
Something happened (capture).
I noticed it (event).
I formed an interpretation of it (derived memory).
That interpretation got linked to other things I already knew (observation memory).
Later, I can find it again (retrieval) — and I can also tell why I have that memory (provenance).
That’s the whole architecture. The repo is the working version of that idea.
The pipeline¶
capture
→ persist
→ emit event
→ derive memory
→ index
→ retrieve
→ inspect trace
That sequence isn’t an aspiration — every arrow is a real route or a real Alembic migration in the repo. You can ingest text or a text-like file, watch the events fire, see derived records appear, query the indexed substrate, and pull back the trace of why a result came back the way it did.
Stack¶
The repo is Docker-first by design. That isn’t preciousness about containers; it’s the only way I trust that the substrate is reproducible across machines.
flowchart LR
Client[Client]
Api[FastAPI API + Jinja UI]
Pg[(PostgreSQL<br/>system of record)]
Redis[(Redis<br/>queue + cache)]
Worker[Indexer Worker<br/>embed + index]
Qdrant[(Qdrant<br/>vector db)]
Client -->|capture / search| Api
Api -->|write canonical data| Pg
Api -->|enqueue index jobs| Redis
Redis -->|job pop| Worker
Worker -->|read item| Pg
Worker -->|upsert vectors| Qdrant
Api -->|keyword search| Pg
Api -->|semantic search| Qdrant
Api -->|cache hot queries| Redis
Piece |
Role |
|---|---|
FastAPI ( |
HTTP surface, Jinja templates, Alembic migrations |
PostgreSQL |
system of record |
Qdrant |
vector retrieval |
Redis |
queue + cache |
Worker ( |
embedding and index jobs |
|
shared DB, search, queue, vector adapters |
The migrations are worth pointing out specifically. 0001_initial, 0002_events_table, 0003_derived_memories, 0004_derived_memory_source_event, 0005_observation_memories, 0006_ingestion_memories — six migrations, each one adds a new layer to the substrate. The order of those migrations is the order I figured out the substrate. Items first. Events on top. Derived memory above that, with a foreign key back to the event that produced it. Then observation memory. Then ingestion memory. That’s the substrate’s history written into its own schema, and it’s the part of this repo I’m most attached to.
Quickstart¶
git clone https://github.com/obversary/memory-dropbox.git
cd memory-dropbox
cp .env.example .env
docker compose up --build -d
Then open:
http://localhost:8000— the three-panel explorer (capture → trail → search/trace)http://localhost:8000/ui/memory— the memory activity feedhttp://localhost:8000/docs— OpenAPI
Tear down:
docker compose down -v # stop and drop volumes
The three-panel UI¶
The web UI is intentionally simple. It has three panels:
Capture — save text or upload a text-like file.
Rabbit Trail — inspect recently captured items.
Search & Trace — search memory and inspect event activity.
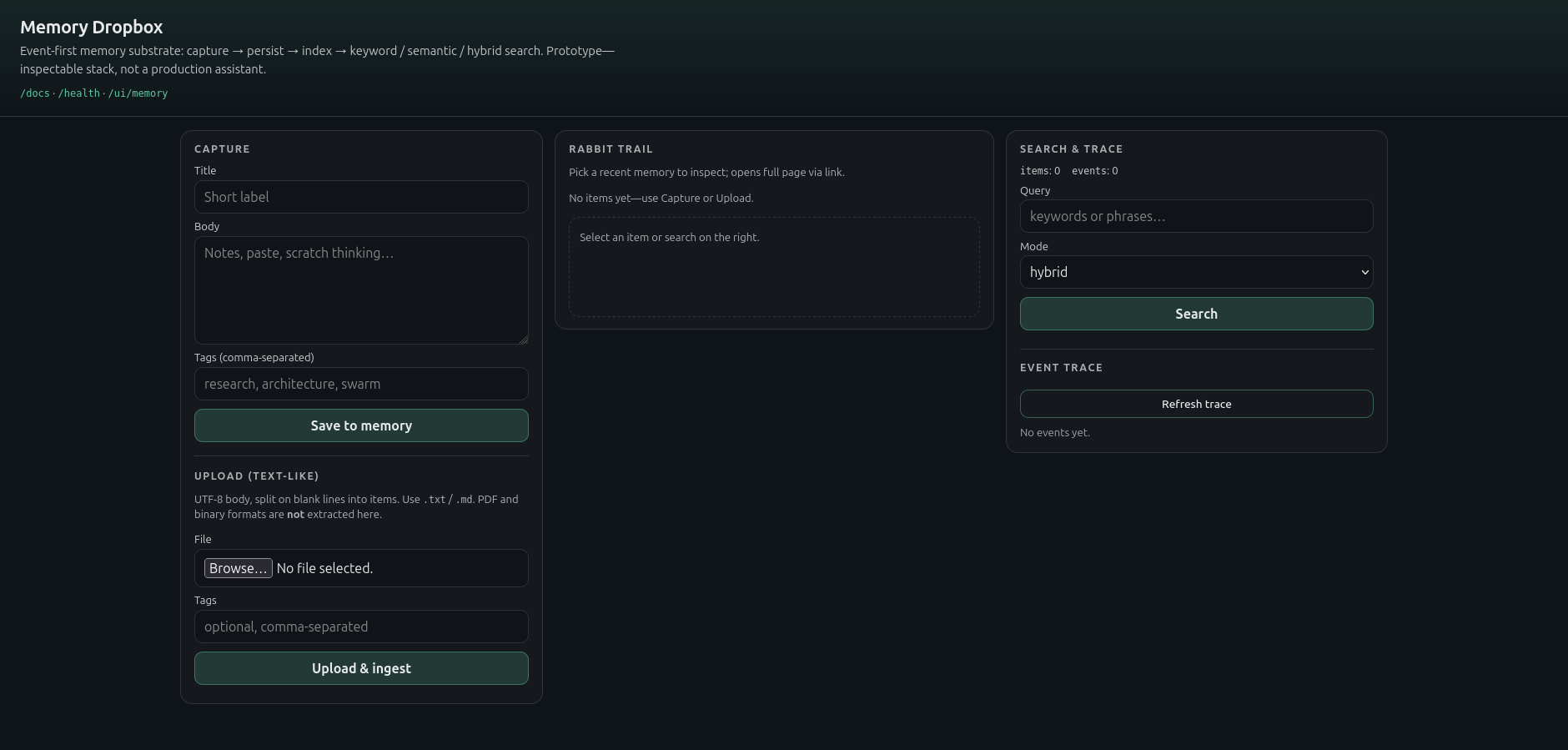
The UI is designed to make the substrate’s behavior visible rather than to be a polished assistant shell. Every panel exposes something the substrate is doing in real time. If a feature isn’t surfacing in one of the three panels, it isn’t really a feature of the substrate yet.
API surface¶
The HTTP routes are organized so the user-facing actions and the inspection actions live in the same surface. That’s deliberate — the inspection layer isn’t a debug tool, it’s a first-class way to use the substrate.
Core capture and retrieval:
POST /ingest/textPOST /ingest/file— text-like files only; the handler reads the upload as UTF-8 and splits on blank lines, no PDF or binary parsing here. Document parsing ispdf-intelligence-core’s job.GET /items,GET /items/{id},PATCH /items/{id}GET /search,GET /search/semantic,GET /search/hybridGET /health
Memory explorer (JSON):
GET /eventsGET /memory/activity— counts (items,events) plus mergedactivityrowsGET /memory/derivedGET /memory/observations
UI:
GET /— three-panel explorerGET /ui/items/{id}— single item view
The OpenAPI documentation is live at /docs:
Search modes¶
Three retrieval paths, each useful for a different kind of question:
Keyword (Postgres FTS) — when you remember the word.
Semantic (Qdrant + deterministic local embeddings) — when you remember the meaning.
Hybrid — when you don’t know which one and want the substrate to fuse the two.
The semantic layer is intentionally lightweight right now — deterministic local embeddings, not a production embedding service. That’s a deliberate choice for the prototype. The shape of the retrieval interface is what matters; the embeddings can be swapped without changing anything above them.
What this demonstrates¶
Event-first memory design, with events as a first-class table.
Persistent item capture with Alembic-tracked schema evolution.
Derived memory records that point back to the event that produced them (foreign key on
derived_memories.source_event_id).Observation and ingestion memory as separate layers.
Searchable memory artifacts (keyword / semantic / hybrid) over the same substrate.
Docker-first local deployment so the substrate is reproducible.
API and UI surfaces designed for inspection alongside use.
What this isn’t¶
Brief. There’s no auth, no production memory platform, no LLM API wiring, no PDF / binary extraction (that’s PDF Intelligence Core’s job), no React SPA — the FastAPI app ships templates only. None of that is hidden. The repo’s README says it plainly and docs/DECISIONS.md says why.
The point of the substrate isn’t to be everything. It’s to be the layer that makes everything else honest.
What this substrate is actually for¶
The substrate is the floor. The interesting work is what stands on it — and the point of building any of this is research speed. A memory substrate that’s honest about provenance and inspectable end to end gives you a better shot at preserving patterns across many artifacts without losing where they came from. The speed claim has to be earned experiment by experiment; the architecture is built so those experiments can be rerun instead of narrated from memory.
A separate article walks through six domains the substrate could be pointed at — crime scene intelligence as the load-bearing stress test, then research operations, engineering incident memory, legal matters, clinical operations, and creative production. Each one is a research question the substrate lets you ask faster, not a product target.
If you want the research-acceleration framing, read What memory substrates are for next.
How this connects to the rest of the stack¶
The three siblings, explicit:
earth-database is the local canonical memory core — small, embedded, SQLite-backed, and the home of the trust-boundary work. When you want the short hot path and the discipline close to the first write, that’s the one.
memory-dropbox (this repo) is the event-sourced substrate experiment — larger, Postgres/Redis/Qdrant/worker, Docker-first. It’s where derived memories, observation memories, and agent-facing memory experiments get tested at a larger scope than fits in one SQLite file.
Obversary-OS is the runtime that is meant to sit on top of both. Today it records decisions in its own event-memory surface; the honest integration work is making those events land in whichever substrate is present without letting the runtime own memory itself.
The applied ingestion lane (PDF Intelligence Core) produces extracted artifacts that are ready for capture. The substrate doesn’t care what produced the text; it cares that it has provenance, an event, and a place to derive memory from.
The evaluation lane (memory-guided eval, structured failure traces) defines the shapes that can make system behavior comparable over time. Failure traces are themselves another layer of memory — the second memory, the one made of mistakes.
The thesis (Why memory is the substrate) is the long version of why this layer exists at all. If memory is what cognition is built from, the substrate is the only place this whole stack can rest its weight.
The point of the substrate isn’t a finished personal assistant. The point is to build the floor that an honest cognitive system could stand on.